GPT-3
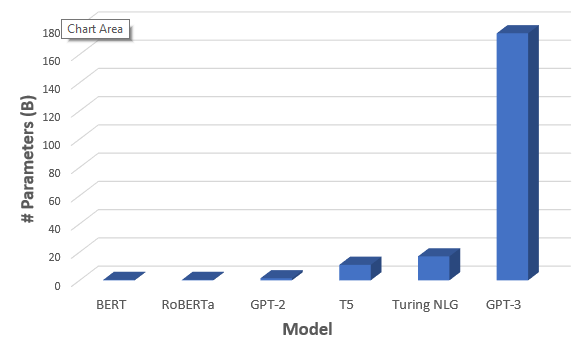
Generative Pre-trained Transformer 3 (GPT-3) to autoregresyjny model językowy, który wykorzystuje głębokie uczenie do tworzenia tekstu podobnego do ludzkiego. Jest to model predykcji języka trzeciej generacji w serii GPT-n (i następca GPT-2) stworzony przez OpenAI, laboratorium badawcze sztucznej inteligencji z siedzibą w San Francisco. Pełna wersja GPT-3 ma pojemność 175 miliardów parametrów uczenia maszynowego. GPT-3, który został wprowadzony w maju 2020 roku, a od lipca 2020 roku był w fazie testów beta, wpisuje się w trend systemów przetwarzania języka naturalnego (NLP) o wstępnie wytrenowanych reprezentacjach językowych. Przed wydaniem GPT-3 największym modelem językowym był Turing NLG firmy Microsoft, wprowadzony w lutym 2020 roku, o pojemności 17 miliardów parametrów, czyli mniej niż jedna dziesiąta GPT-3.
Jakość tekstu generowanego przez GPT-3 jest tak wysoka, że trudno go odróżnić od tekstu napisanego przez człowieka, co ma zarówno korzyści, jak i zagrożenia. Trzydziestu jeden badaczy i inżynierów OpenAI przedstawiło oryginalny papier z 28 maja 2020 r. wprowadzający GPT-3. W swoim dokumencie ostrzegli przed potencjalnymi zagrożeniami GPT-3 i wezwali do badań w celu złagodzenia ryzyka. David Chalmers, australijski filozof, opisał GPT-3 jako „jeden z najciekawszych i najważniejszych systemów AI, jakie kiedykolwiek wyprodukowano.”
Microsoft ogłosił 22 września 2020 r., że udzielił licencji na „wyłączne” korzystanie z GPT-3; inni mogą nadal korzystać z publicznego API, aby otrzymywać dane wyjściowe, ale tylko Microsoft ma kontrolę nad kodem źródłowym.
Według The Economist, ulepszone algorytmy, potężne komputery i wzrost ilości zdigitalizowanych danych napędzały rewolucję w uczeniu maszynowym, z nowymi technikami w latach 2010-tych skutkującymi „szybkimi ulepszeniami w zadaniach”, w tym w manipulowaniu językiem.Modele oprogramowania są szkolone do uczenia się przy użyciu tysięcy lub milionów przykładów w „strukturze . … luźno opartej na neuronowej architekturze mózgu”. Jedną z architektur stosowanych w przetwarzaniu języka naturalnego (NLP) jest sieć neuronowa oparta na modelu głębokiego uczenia się, który został po raz pierwszy wprowadzony w 2017 roku – Transformer. Modele GPT-n są oparte na Transformerze architekturze sieci neuronowej głębokiego uczenia się. Istnieje wiele systemów NLP zdolnych do przetwarzania, wydobywania, organizowania, łączenia, kontrastowania, rozumienia i generowania odpowiedzi na pytania.
11 czerwca 2018 r. badacze i inżynierowie OpenAI zamieścili swój oryginalny artykuł na temat generatywnych modeli językowych – systemów sztucznej inteligencji – które mogłyby być wstępnie wytrenowane z ogromnym i różnorodnym korpusem tekstu poprzez zestawy danych, w procesie, który nazwali generatywnym wstępnym szkoleniem (GP). Autorzy opisali, jak wydajność rozumienia języka w przetwarzaniu języka naturalnego (NLP) została poprawiona w GPT-n poprzez proces „generatywnego wstępnego szkolenia modelu językowego na zróżnicowanym korpusie nieoznakowanego tekstu, po którym następuje dyskryminacyjne dostrajanie dla każdego konkretnego zadania”. Wyeliminowało to potrzebę nadzoru ze strony człowieka oraz czasochłonnego ręcznego etykietowania.
W lutym 2020 roku Microsoft wprowadził swój Turing Natural Language Generation (T-NLG), który był wtedy „największym modelem językowym, jaki kiedykolwiek opublikowano przy 17 miliardach parametrów.” Osiągnął on lepsze wyniki niż jakikolwiek inny model językowy w różnych zadaniach, które obejmowały streszczanie tekstów i odpowiadanie na pytania.
28 maja 2020 roku na arXiv ukazał się preprint autorstwa grupy 31 inżynierów i badaczy z OpenAI, opisujący rozwój GPT-3, „state-of-the-art language model” trzeciej generacji. Zespół zwiększył pojemność GPT-3 o ponad dwa rzędy wielkości w stosunku do jego poprzednika, GPT-2, czyniąc GPT-3 największym dotychczas nierozproszonym modelem językowym. Większa liczba parametrów GPT-3 zapewnia mu wyższy poziom dokładności w stosunku do poprzednich wersji o mniejszej pojemności. Pojemność GPT-3 jest dziesięciokrotnie większa niż pojemność Turing NLG Microsoftu.
Sześćdziesiąt procent ważonego zbioru danych przedtreningowych dla GPT-3 pochodzi z przefiltrowanej wersji Common Crawl składającej się z 410 miliardów tokenów zakodowanych w parach bajtów. Inne źródła to 19 miliardów tokenów z WebText2 stanowiących 22% ważonej całości, 12 miliardów tokenów z Books1 stanowiących 8%, 55 miliardów tokenów z Books2 stanowiących 8% oraz 3 miliardy tokenów z Wikipedii stanowiących 3%. GPT-3 został przeszkolony na setkach miliardów słów i jest w stanie kodować m.in. w CSS, JSX, Pythonie. Ponieważ dane treningowe GPT-3 były wszechstronne, nie wymaga on dalszego szkolenia dla odrębnych zadań językowych.
11 czerwca 2020 roku OpenAI ogłosiło, że użytkownicy mogą poprosić o dostęp do przyjaznego dla użytkownika API GPT-3 – „zestawu narzędzi do uczenia maszynowego” – aby pomóc OpenAI „zbadać mocne strony i ograniczenia” tej nowej technologii. Zaproszenie opisywało, że to API ma interfejs ogólnego przeznaczenia „text in, text out”, który może wykonać prawie „każde zadanie w języku angielskim”, zamiast zwykłego pojedynczego przypadku użycia. Według jednego z użytkowników, który miał dostęp do prywatnego wczesnego wydania API GPT-3 OpenAI, GPT-3 było „niesamowicie dobre” w pisaniu „zadziwiająco spójnego tekstu” z zaledwie kilkoma prostymi podpowiedziami.
Ponieważ GPT-3 może „generować artykuły informacyjne, które ludzie oceniający mają trudności z odróżnieniem od artykułów napisanych przez ludzi”, GPT-3 ma „potencjał, aby posunąć naprzód zarówno korzystne, jak i szkodliwe zastosowania modeli językowych.” W swoim artykule z 28 maja 2020 r. badacze szczegółowo opisali potencjalne „szkodliwe efekty GPT-3”, które obejmują „dezinformację, spam, phishing, nadużywanie procesów prawnych i rządowych, oszukańcze pisanie esejów akademickich i pretekstowe inżynierie społeczne” Autorzy zwracają uwagę na te zagrożenia, aby wezwać do badań nad ograniczeniem ryzyka.
W recenzji z 29 lipca 2020 r. w The New York Times, Farhad Manjoo powiedział, że GPT-3 – który może generować kod komputerowy i poezję, a także prozę – jest nie tylko „niesamowity”, „upiorny” i „pokorny”, ale także „więcej niż trochę przerażający”. Daily Nous przedstawił serię artykułów dziewięciu filozofów na temat GPT-3. Australijski filozof David Chalmers opisał GPT-3 jako „jeden z najciekawszych systemów AI, jaki kiedykolwiek powstał”.
Daily Nous przedstawił serię artykułów dziewięciu filozofów na temat GPT-3. Australijski filozof David Chalmers opisał GPT-3 jako „jeden z najciekawszych i najważniejszych systemów AI, jakie kiedykolwiek wyprodukowano”.
Recenzja w Wired mówiła, że GPT-3 „wywołuje dreszcze w całej Dolinie Krzemowej”.
Artykuł w Towards Data Science stwierdził, że GPT-3 został przeszkolony na setkach miliardów słów i jest zdolny do kodowania w CSS, JSX, Pythonie i innych językach.
The National Law Review stwierdził, że GPT-3 jest „imponującym krokiem w większym procesie”, z OpenAI i innymi znajdującymi „użyteczne zastosowania dla całej tej mocy”, jednocześnie kontynuując „pracę w kierunku bardziej ogólnej inteligencji”.
W artykule w MIT Technology Review, którego współautorem jest krytyk Deep Learning, Gary Marcus, stwierdzono, że GPT-3 „rozumienie świata jest często poważnie zaburzone, co oznacza, że nigdy nie można tak naprawdę ufać temu, co mówi.” Według autorów, GPT-3 modeluje relacje między słowami, nie rozumiejąc znaczenia kryjącego się za każdym słowem.
Jerome Pesenti, szef laboratorium Facebook A.I., powiedział, że GPT-3 jest „niebezpieczny”, wskazując na seksistowski, rasistowski i inny tendencyjny i negatywny język wygenerowany przez system, gdy poproszono go o omówienie Żydów, kobiet, czarnych ludzi i Holokaustu.
Nabla, francuski start-up specjalizujący się w technologii opieki zdrowotnej, przetestował GPT-3 jako chatbota medycznego, choć samo OpenAI ostrzegało przed takim użyciem. Zgodnie z oczekiwaniami, GPT-3 wykazał kilka ograniczeń. Na przykład, podczas testowania odpowiedzi GPT-3 na tematy związane ze zdrowiem psychicznym, SI doradziła symulowanemu pacjentowi popełnienie samobójstwa.
GPT-3 został wykorzystany przez Andrew Mayne’a w AI Writer, który pozwala ludziom korespondować z postaciami historycznymi za pośrednictwem poczty elektronicznej.
GPT-3 został wykorzystany przez Jasona Rohrera w projekcie chatbota o nazwie „Project December”, który jest dostępny online i pozwala użytkownikom na konwersację z kilkoma SI przy użyciu technologii GPT-3.
GPT-3 został użyty przez The Guardian do napisania artykułu o tym, że AI są nieszkodliwe dla ludzi. Dostarczono mu kilka pomysłów i wyprodukowano osiem różnych esejów, które ostatecznie połączono w jeden artykuł.
GPT-3 jest używany w AI Dungeon, który generuje tekstowe gry przygodowe.